The dataflow model is a computation model where instructions execute as soon as their input data is available.
This is different from a traditional sequential processor, where instructions usually execute in program order.
Main idea
In the dataflow model:
- an operation is triggered by the availability of its operands
- the program can be viewed as a graph
- nodes represent operations
- edges represent data dependencies
This means the execution order is determined by the flow of data, not mainly by the order of instructions in memory.
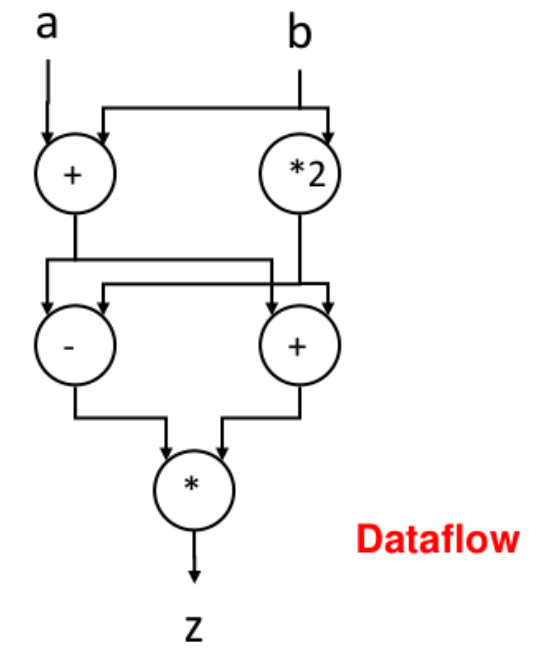
Example intuition
If an instruction needs the results of two previous computations, it waits until both values are ready.
As soon as both inputs arrive, the instruction can execute immediately.
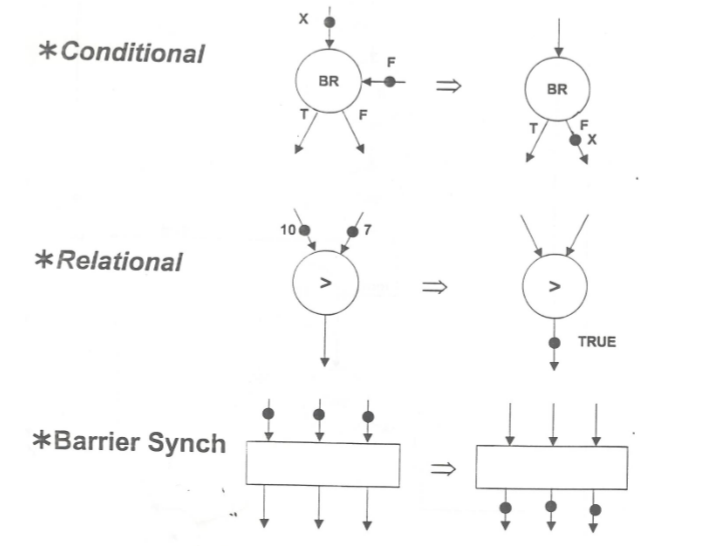
Basic Components:
Advantages
- exposes a lot of parallelism
- avoids unnecessary waiting for unrelated instructions
- matches dependency-based execution well
Disadvantages
- hardware and scheduling are more complex
- managing tokens, dependencies, and communication is difficult
- less common as a full machine model in practice
Comparison with von Neumann model
The von Neumann Model model is based on a sequential stream of instructions stored in memory.
In a von Neumann machine:
- instructions are fetched from memory one after another
- execution is mainly driven by the program counter
- memory stores both instructions and data
In a dataflow machine:
- execution is driven by data dependencies
- independent operations can run in parallel
- there is no central focus on sequential instruction order
Short comparison
| Model | Execution trigger | Typical behavior |
|---|---|---|
| Dataflow model | Input data becomes available | Naturally parallel |
| von Neumann model | Program counter selects next instruction | Mostly sequential |